I Am Graphics And So Can You :: Part 5 :: Your Pixels Are Served

There they go... draw calls piling into a command buffer; waiting to be pushed in batch to their next stage in the pipeline. When you call draw, you're not actually invoking anything on the GPU directly. Instead you're recording things to a command buffer which will later be submitted. The GPU is very good at what it does, but it's too busy to stand around and have a conversation with just you.
Remember my restaurant analogy a couple posts back? The CPU would be akin to the server writing your order down into a small buffer. When you say you're done and want to submit your order, the server then takes that back to the kitchen; which in this analogy is the GPU. The GPU is setup to produce orders as quickly and efficiently as possible.
In Part 4.5 we discussed how and where idTech invokes draw calls and we stopped just short of diving into the Vulkan specific parts. So let's order us up some pixels! It only takes a few simple steps.
- Start a frame
- Record draw calls
- End a frame
- Submit to GPU
- Wait for work to be done, then show to user.
In restaurant parlance this would be...
- Server pulls out pad and pen.
- Server writes down your order.
- Server finishes taking your order.
- Server takes order to the kitchen.
- Server waits for food to be done, then brings it to you.
In code this will be...
- GL_StartFrame
- DrawView, CopyRender, PostProcess
- GL_EndFrame
- vkQueueSubmit ( Also in GL_EndFrame )
- BlockingSwapBuffers
Start A Frame

Let's order us up some pixels!
So a lot of unsurprising things, and then something kinda scary for beginners. ( pipeline barriers ). Don't worry, it'll all make sense in a bit. But first let's talk about the unsurprising things.
- vkAcquireNextImageKHR - We just get the swapchain image we'll be rendering our frame into.
- Resolve any memory operations that were deferred. This includes image / memory deletions or staged allocations.
- vkBeginCommandBuffer - We open the command buffer so we can begin recording things into it.
- vkCmdBeginRenderPass - We open the renderpass so we can begin drawing to its attachment(s). Notice the command buffer we opened is passed to the function as the first parameter. Also note the call begins with vkCmd. This is a very common idiom for functions recording things to a command buffer.
So now for the scary bit.
Pipeline Barriers
We briefly touched on pipeline barriers in image allocations. But it was easy to "hand wave" them away as just transitioning the image layouts. Now we're forced to answer a more fundamental question about what it is doing. One of the core differences of Vulkan from earlier graphics APIs is that you have to provide your own synchronization when accessing data.
So before I dive into explaining pipeline barriers, I'll give you the short answer. They help you keep your memory consistent by avoiding three deadly hazards.

Let's go back to our restaurant analogy. In this case pipeline barriers actually apply to what's going on in the kitchen. This is because in essence the kitchen is a pipeline. It has stages of food prep and delivery. If anyone messes up at any stage then someone's order can come out wrong, and we've all been there. Let's setup a fake kitchen and examine how pipeline barriers save your meal.

Here's our kitchen, and a quaint little restaurant. We've already got two customers! One is vegetarian ( denoted by a green circle ) and one is meat-eating ( denoted by a red circle ). Obviously vegetarians would be rather displeased if their meal showed up with meat on it. And someone ordering a dish containing meat would be displeased to not receive such.
So there's a rather nice comparison already to a discrete GPU setup. Let's look at that real quick.

Although in reality the GPU would look more like this.

Now in our restaurant things are rather simple. There's always a vegetarian table making a vegetarian order, and there's always a non-vegetarian table ordering non-vegetarian things. Their hunger is never satiated so they just order the same thing over and over again. The vegetarian order always gets submitted before the non-vegetarian one. The kitchen is composed of three stages.
- Prep Stage - Prepares the same ingredients for an order no matter what.
- Line Stage - Cooks either the vegetarian or non-vegetarian main course.
- Expediter Stage - Puts the dish together and gives it back to the server.
Let's walk through how the kitchen handles orders without any problems.
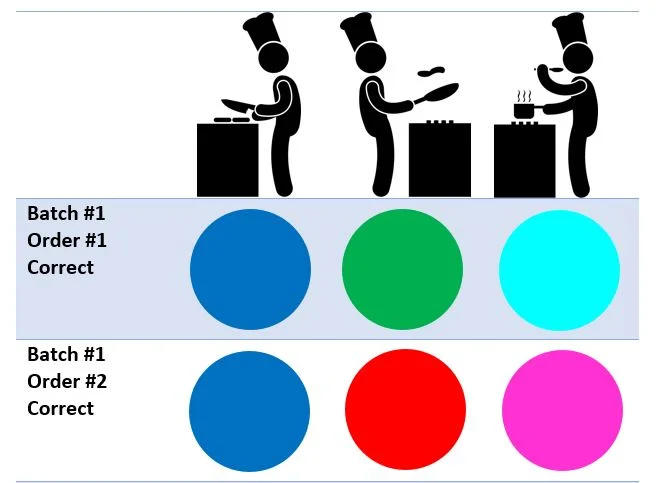
Let's examine how our kitchen functions under ideal conditions. The prep stage always prepares garnish ingredients that go on our food no matter veg/non-veg. This is represented by blue. The line stage cooks either veg/non-veg, represented by green and red. The expediter stage mixes the ingredients to show a final outcome matching what the recipe should produce ( cyan = veg dish, magenta = non-veg ). Remember that veg orders are submitted first so blue shaded rows should always have cyan as a result. White shaded rows ( even orders ) are non-veg and should have magenta as a result. Now let's look at some problems that can occur in the pipeline.
Read-After-Write

Oops! The kitchen just gave someone a vegetarian dish when they didn't order it. What happened? In this case they got the first order right. But on the second one the expediter READ from the line stage before the line had a chance to WRITE red. That means they got the old ingredients. Most modern hardware ( and GPUs in particular ) are highly concurrent. But as experienced hands can tell you, this often leads to unexpected side effects if not managed properly. Sometimes we need to guarantee order of operations. This is essentially what pipeline barriers help with.
Write-After-Read
This next hazard is very similar to the first, it's just reversed. Instead of the READ happening before the WRITE, the WRITE beats out the READ when we don't want it to.

This kitchen is just falling apart. What mess have they gotten into now? Well what happened is that the orders overlapped to where the line stage wrote before the expediter had a chance to read. This resulted in two non-veg dishes.
Write-After-Write
Now for the final hazard that can befall our kitchen. We'll need to expand our pipeline a bit to demonstrate this one. Say we add a grill stage after the line stage. The grill only works on results of the line stage. ( Grilled results are teal = grilled veg and purple = grilled non-veg )

Well at least prep continues to do their job right. What mess are we into now? Well for one we had two orders come out not cooked. Why is that? The grill stage got executed before the line stage. That means when the line stage wrote, it overwrote the result of the grill stage. When the expediter came along, they only found non grilled ingredients but proceeded with mixing anyways. Everyone is mad now, including the executive chef. Expect 1 start reviews on Yelp. So WaW basically means that the order of writes gets swapped and the final reader gets a different result than expected.
So let's now break down vkCmdPipelineBarrier as though we were applying it to our kitchen. ( Using a recently launched Vulkan Kitchen API ).
What this does is it guards each order so READS/WRITES stay consistent within a given order. For example we say that as soon as the WAITER_WRITE_BIT is triggered we start guarding those operations through prep, line, and expediter READS/WRITES. We guard them at each stage of the pipeline using PIPELINE_STAGE_ALL.
Now is this optimal? No. As a matter of fact it's very heavy handed. We're guaranteeing operations at every stage of the pipeline and we're not allowing orders to overlap. Where would be a good place to optimize things? As you may have noticed in all our examples, none of the hazards were caused in Prep. This is because the results are always the same. So we wouldn't need to guarantee READS/WRITES for this stage. The kitchen could start on two orders simultaneously and then guarantee operations starting at the line stage.
This may seem rather complicated, and it is! But unless you're doing something super sophisticated, you only need to understand it in a few places. I've already pointed out where it's useful for images, and now I've pointed out where it's useful for memory. The main purpose of this pipeline is to guard operations for each frame. There are only three places where VkNeo uses pipeline barriers. And the final one we haven't covered is in post processing ( which is also related to image transitions ).
So take heart. The time to investigate this type of synchronization is warranted when you start seeing graphical glitches or odd crashes. Be sure to check your validation layer output as well as it can be helpful in this regard.
Render A Frame

Here it is. This is where the rubber meets the road. Drawing. In Part 4.5 we stopped at DrawElementsWithCounters. Now we'll take the plunge. Everything lead up to this.
A bit underwhelming right? Just like all things Vulkan, the effort is front loaded so the actual workload is minimum. So let's reiterate the steps in non technical terms.
- Get the portion of the vertex buffer that contains the surface we want to draw.
- Get the portion of the index buffer that contains the indices into the vertex buffer.
- Get the index offset we start at.
- Validate that our current graphics pipeline can bind a joint buffer if there is one.
- Save off the joint buffer handle.
- Commit the current graphics pipeline state ( covered in next article ).
- Bind index buffer
- Bind vertex buffer
- Draw indexed
There's only one other place in VkNeo that issues draw calls and that is in drawing the stencil shadow pass. But we won't cover that in this post. To accentuate the simplicity of this section of code I shall now move on.
End A Frame

We've done it! We wrote a frame. We stopped at a kitchen and got the wrong order too. ( I haven't been playing overcooked, no way. ) All that's left is to wrap things up and send it off to the GPU. Let's take care of that now.
Again straight forward. Now the GPU is busy producing our frame. Oh wait, how do we present it!
Swap Buffers & Present

We have one last thing to do, and that's show off our handy work. Here's how we go about that.

BOOM! It's all coming together isn't it? We only have one major topic to cover before we start getting into the weeds. Next up we'll dissect idRenderProgManager and see just what it's been hiding this whole time. And believe me, it's more important and far more fascinating than this post here. That's because we'll be looking at how we actually control the graphics pipeline itself. We'll be knee deep in the GPU. Stay tuned. Oh and Pixels are served.